Python PDF Library Text Extraction from PDFs
Python Extract Text from PDF 2023.10.3
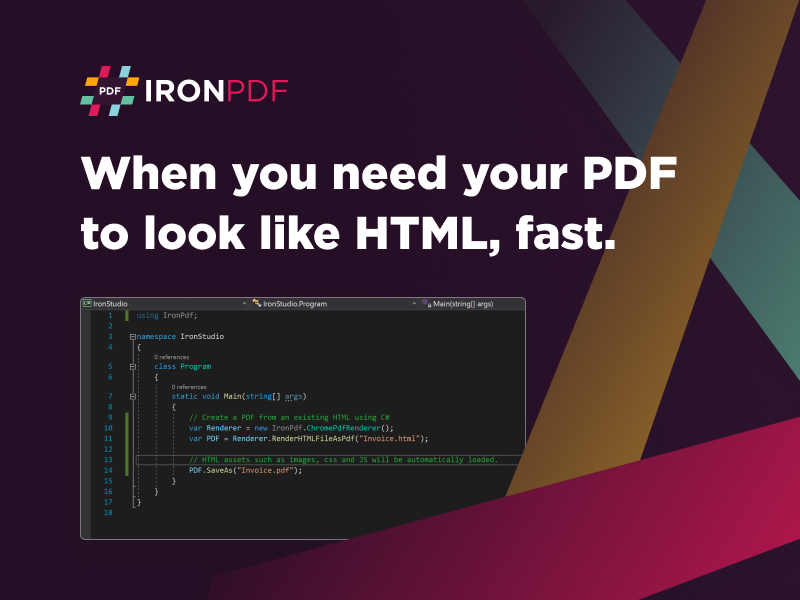
The Python PDF Library offers developers a robust solution for extracting text from PDFs, simplifying this intricate process. With its intuitive APIs and utilities, this library empowers developers to seamlessly extract textual content from PDFs and integrate it into their Python applications.
Text extraction involves identifying and extracting the textual content present in a PDF document, including paragraphs, headings, and other elements. The Python PDF Library streamlines this process, providing developers with methods to accurately identify and extract text from PDFs. Developers can customize the text extraction process based on specific project requirements, allowing for flexibility in handling various types of PDFs and ensuring accurate text extraction. The Python PDF Library offers the tools needed to tailor the extraction according to the document's structure, fonts, languages, and other parameters, ensuring a consistent and reliable text extraction experience.
To embark on the journey of integrating text extraction into your Python workflow using the Python PDF Library, you can follow a comprehensive tutorial available https://ironpdf.com/python/blog/using-ironpdf-for-python/python-extract-text-from-pdf. This tutorial offers step-by-step guidance, code examples, and best practices for effectively integrating the library into your applications. It equips you with the knowledge and tools to master text extraction from PDFs in Python and enhance your data processing and analysis capabilities.
The ability to extract text from PDFs is a fundamental feature for various applications requiring data processing and analysis. Python, with its versatile set of libraries, provides an efficient and effective way to achieve this extraction. By leveraging the capabilities of the Python PDF Library, developers can seamlessly integrate text extraction from PDFs into their Python applications, enabling streamlined data processing and analysis for a wide range of projects.
Text extraction involves identifying and extracting the textual content present in a PDF document, including paragraphs, headings, and other elements. The Python PDF Library streamlines this process, providing developers with methods to accurately identify and extract text from PDFs. Developers can customize the text extraction process based on specific project requirements, allowing for flexibility in handling various types of PDFs and ensuring accurate text extraction. The Python PDF Library offers the tools needed to tailor the extraction according to the document's structure, fonts, languages, and other parameters, ensuring a consistent and reliable text extraction experience.
To embark on the journey of integrating text extraction into your Python workflow using the Python PDF Library, you can follow a comprehensive tutorial available https://ironpdf.com/python/blog/using-ironpdf-for-python/python-extract-text-from-pdf. This tutorial offers step-by-step guidance, code examples, and best practices for effectively integrating the library into your applications. It equips you with the knowledge and tools to master text extraction from PDFs in Python and enhance your data processing and analysis capabilities.
The ability to extract text from PDFs is a fundamental feature for various applications requiring data processing and analysis. Python, with its versatile set of libraries, provides an efficient and effective way to achieve this extraction. By leveraging the capabilities of the Python PDF Library, developers can seamlessly integrate text extraction from PDFs into their Python applications, enabling streamlined data processing and analysis for a wide range of projects.
Ключевые слова:
python extract text from pdf, extract text from pdf python